Evaluation Metric
macro f1 score : 각 클래스에 대한 f1 score 개별적 계산 후, 평균

Data Overview
train data : 1570 < test data : 3140
- train.csv : 학습 이미지 이름 & 클래스 사이 mapping 정보
- meta.csv : 클래스 이름 & 인덱스 간 mapping 정보
- train/: 학습이미지 경로
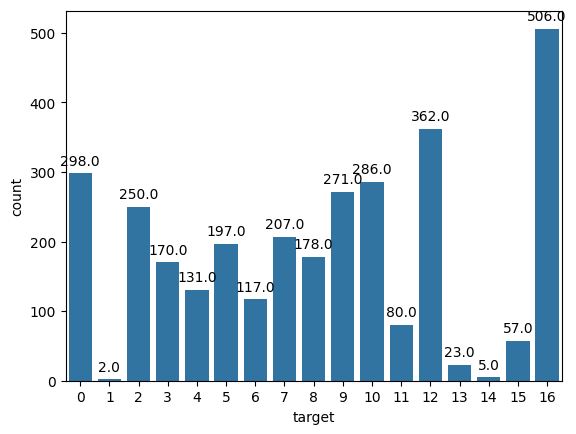
총 17개, 각 class 별 46~100장 (class별 수량이 다름)
2개 클래스는 차량사진임
0. 계좌번호 (Account Number)
1. 임신 의료비 지불 신청서 (Application for Payment of Pregnancy Medical Expenses)
2. 차량 계기판 (Car Dashboard)
3. 입원 및 퇴원 확인서 (Confirmation of Admission and Discharge)
4. 진단서 (Diagnosis)
5. 운전면허증 (Driver’s License)
6. 의료 비용 영수증 (Medical Bill Receipts)
7. 외래 진료 증명서 (Medical Outpatient Certificate)
8.주민등록증 (National ID Card)
9. 여권 (Passport)
10. 결제 확인서 (Payment Confirmation)
11. 의약품 영수증 (Pharmaceutical Receipt)
12. 처방전 (Prescription)
13. 이력서 (Resume)
14. 의견서 (Statement of Opinion)
15. 차량 등록증 (Vehicle Registration Certificate)
16. 차량 등록 번호판 (Vehicle Registration Plate)
train data
정방향의 clean한 데이터
개인정보는 마스킹처리 되어있음
test data
여러 Albumentation 기법 적용하여 noise가 껴있는 상태
Insight & Idea
class별 data가 불균형하여 학습시 이를 해소할 수 있는 방법 찾아야
→ augmentation 기법 사용하여 data 수량을 늘리며 overfitting 방지할 수 있도록
개인정보 마스킹화
→ black boxing이 학습에 영향 주는 요소 있는지 확인이 필요할 듯함
어떤 augmentations는 seceret → EDA 통해서 찾아봐야함
+
augmentation 기법을 적용한 일관적인 규칙이 있을 수 있음
→ 회전각도, 명도, 감마 등 유형별로 정리하여 빈도 높은 순으로 train data에 적용하여 학습하는 방법?
→ augmentation 기법이 독특한 케이스들 or noise가 심한 case는 제거하는 방법도
+
test data에 적용한 augmentation 기법별로 모델을 만들어 ensemble 하면 좋을듯
(가장 성능이 좋았던 모델에 가중값을 주는 등)
++ 추가내용
train data 수량중 1, 13, 14 class만 수량이 적어서 해당 클래스만 보완해주면 될지도

test data 상 차량 관련 class(16,2 등)를 제외하고 학습하는 건 힘들듯
Reference
albumentation 기법종류 참고용
https://hoya012.github.io/blog/albumentation_tutorial/
albumentations - fast image augmentation library 소개 및 사용법 Tutorial
image augmentation library인 albumentations에 대한 소개와 사용 방법을 Tutorial로 정리해보았습니다.
hoya012.github.io
강좌에서 언급된 alubmentation 라이브러리 / 기법 참고용
https://github.com/sparkfish/augraphy
GitHub - sparkfish/augraphy: Augmentation pipeline for rendering synthetic paper printing, faxing, scanning and copy machine pro
Augmentation pipeline for rendering synthetic paper printing, faxing, scanning and copy machine processes - sparkfish/augraphy
github.com
'일별 학습일지' 카테고리의 다른 글
| 4/23 :: Fast-up report (0) | 2024.04.27 |
|---|---|
| 4/12~4/13 :: Ideation (0) | 2024.04.14 |
| 4/5 :: CV (0) | 2024.04.05 |
| ML Competition : Fast-UP Report (0) | 2024.04.03 |
| 3/20~4/2 :: ML Competition (0) | 2024.04.03 |

