김용담 강사님
약 2월까지 머신러닝 같이 진행하려함
진행방식
45/15
오전만 강의가 있거나, 오후만 강의가 있는 경우가 있음
계속해서 하면 지치다보니 5타임 이후엔 30분 정도 쉬고 이어서 진행해서 7시에 끝남
7시보다 5분정도 일찍 끝나게 될거임.
바로 다음주부터 EDA 프로젝트 진행함
어느정도 numpy, pandas를
EDA에 관련된 내용, 시각화를 이번주까지 할듯
데이터셋을 찾아서 관련된 어떤 특징이 있는지,
가상환경 설정 > 폴더별 설정하려고 쓰는 것 맞음
버전이 다 다르게 들어감
여러개 버전을 한꺼번에 쓰는 용도
도커 이미지?
특정시스템을 한번에 설치해야되는 경우도 있음
(라이브러리 및 시스템 환경설정까지 설치해야하는 경우)
도커에서 실행을
Numpy
파일경로
http://localhost:8888/notebooks/Desktop/AI_Lab/jupyter/Numpy/2.%20Numpy%20%EA%B8%B0%EC%B4%88(%EC%8B%A4%EC%8A%B5).ipynb
파이썬 내에서 float 형 실수 계산을 해버리면 오류가 많이 발생하게 됨
즉 수치계산을 위해서 쓰는 라이브러리
Powerful N-DIMENSIONAL ARRAYS
벡터 계산
pandas, scipy, scikit-learn, tensorflow, pytorch
pandas 1.5.3 // pandas 2.0.3
pandas 1.x VS pandas 2.x (대용양처리가 빠름)
Numpy를 직접적으로 사용하는 라이브러리, Ecosystem
Numpy array 에 대한 이해
연산(broadcasting, method 함수)
연산의 사용처
AI를 접을 때까지 쓸 4가지
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
파이썬의 특징 : dynamic ~
단점 : 어떤 연산을 하던간에 dtype을 다 비교해야됨
= 몇 억개 연산 쯤 되면 비교로 인해 연산이 많이 느려짐
numpy는 비교할 필요 없게 미리 정해버림 > 연산시간 빠름
1. 메모리 접근 효율성
2. broadcasting 연산이 빨라지는 이유
multi-threading
물리적으로 동시에 쓰게하는 방법
(엔비디아 100만원대 쓰면 thread 개수가 1만개 등 됨)
리스트 안의 리스트.. 차원
물리학에서 정보가 담겨 있는 차원
1차원 : 벡터
2차원 행렬 : matrix
3차원 tensor
머신러닝까지는 2차원 매트릭스를 많이 씀
1.4. Array Arithmetic (like vector) --> Universal Function
익숙해지는데 시간을 투자할 것을 추천함
cf. 리스트에서의 연산 Concatenation
더하기 연산은 2개가 붙어서 새로운 리스트가 나오는 것
vs
연장 .extend() 함수를 활용한 것

#list로 구현하려면 길어짐
[n1 + n2 for n1, n2 in zip([1,2,3], [4,5,6])]
#np.array면 간단하게
[1,2,3] + [4,5,6]
# dot product : 같은 위치에 있는 원소들을 각자 곱하고, 모두 더한 결과.
v1 @ v2
shape의 개념을 인지
(3,) : 벡터 != (3,1)
일단 행,렬의 개념으로 계산하지마라
바깥의 대괄호의 원소 순서대로 계산
arr1 = np.array([
[
[1,1],
[2,2],
[3,3],
],
[
[4,4],
[5,5],
[6,6]
]
])
# arr1.shape : (2,3,2)
(2,3,2) = 2개 x (3,2)
(3,2) = 3개 (2,)
# img (pixel map) 경우
arr1 = np.array(
[[1,2,3],
[4,5,6],
[7,8,9]]
)
#arr1.shape : (3,3)
arr2 = np.array(
[[1,2,3],
[4,5,6],
[7,8,9]], # Red channel
[[1,2,3],
[4,5,6],
[7,8,9]], # Blue channel
[[1,2,3],
[4,5,6],
[7,8,9]], # Green channel
)
#arr2.shape : (3, 3,3)
# RGB-channel > 3x3
# 32x32 크기의 color image 100장이 있다면? (100,3,32,32)
shape를 한번 제대로 이해해야됨
데이터가 계산되는 방식
Q. rgb를 하나의 값으로 관리하지 않고 3개 배열로 관리하는 이유가 있나요?
A.
엄밀하게 이야기하면 구현 방식에 따라 다름
+
관리하기 편하게, 연산정의상 편하게 등
24bit true color = 8bit x 3
나중에는 실수값으로도 함.

Python은 제대로 구해도 효율이 안좋음
결과적으로 bit 연산을 한다해도 word 단위로 진행되다보니 똑같음
하지만 bit 연산은 코딩이 어려움 = coding advantage를 고려할 때 np.array() 방식으로 하는게 효율적이다.
float32, float64
single precision, double precision
IEEE754 : floating point precision (컴퓨터가 소수점을 표시하는 국제 표준)
유효숫자 기준
32bit : 12자리
64bit : 24자리
quantization
딥러닝 인기분야 : 메모리 아낄 수 있음 good
실수값을 정수로해서 데이터의 충분한 패턴을 표현할 수 있느냐의 문제
array의 차원이 다른경우의 연산
연산정의를 할 때 이를 활용해 계산 뿌리는 경우 많음
- Universal Function : broadcast 기능을 확장해서, numpy array의 모든 원소에 동일한 함수를 반복문으로 적용한 것과 같은 효과를 내는 기능.
활용하면 되게 편할듯 = "우리가" for 문을 쓸 필요가 없음
참고
numpy에서는 col, row 란 개념이 없음
numpy array는 .T 써서 transpose를 해도 하는 것은 똑같음
연산정의를 할 때 연산의 순서를 알고 있으면
만들고 싶은 수식을 어떻게 numpy로 만들 수 있을까
1. shape 이 100% 일치
2. dimension 차원이 일치
shape으로 볼때
ex) 앞쪽 shape 이 똑같은 것은 의미가 없고, 뒤에가 같아야함
(3,2,3) (2,3) 은 됨 # 3 x (2,3) = (2,3)
(3,2,3) (2,2) 는 안됨 # 3 x (2,3) !=(2,2) why? 1차원 shape이 다르기 때문
broadcast는 벡터 단위로 계산 = 밑에 것이 같아야함
cf) shape이 1인 경우, 생각을 다르게 해야됨. 연산의 기준이 다름
> 익숙해지면 생각을 해봐도 좋음
matrix multiplication 해보시면 이해할듯함
cf. 넘파이생성 관련
넘파이 난수 생성 알고리즘이 대략적으로 말하면 첫 숫자를 기준으로 특정 점화식을 기준으로 파라미터를 생성하고 그 파라미터들을 기준으로 난수를 생성하는데, seed는 그 첫 숫자를 seed로 고정하기 때문에 항상 같은 난수를 생성할 수 있습니다. (한주형 님)
Numpy Methods 함수
numpy random table 난수표?는 생각해본 적은 없음
어떤 수를 쓰냐에 따라서 달라지기에 의미가 없다
푸리에 변환을 해보고 싶다?
라이브러리의 구현 코드가 이미 있어서 쓰면 된다.
numpy에서는 축을 어떻게 보는 지에 따라 값이 다름
axis=0, column 방향
axis=1, row방향
Index의 방향을 인지해야됨

3. Performance Check
돌리는 연산에선 평균적으로 Universal Function이 for 반복문보다 700배 정도 빠름
단위가 다름 s vs ms
numpy를 쓸때는 universal function을 익히는 연습을 해야됨
Q. rand vs randn
정규분포 vs 균일분포
(점심시간 후엔 간단 numpy 구현 )
Q. 저희는 파이썬으로 코딩을 하는데 c언어로 된 라이브러리를 쓰는게 잘 이해가 안되는데요
A.
'언어론'에서 언어의 개념을 가져온 것
Python은 tool 이 아니라 programming language 이다.
어떤 목적에 따라 만들어진
0,1 규칙을 부여하여 logic gate 회로 레벨에서 전압레벨로 true, false 를
몇십 몇조개의 회로가 들어간 메모리를 사용하는 것
computational 구조로 구현가능
C
1972년 운영체제를 위한 언어 / 메모리 접근
하드웨어에 가깝게 되어 있기 때문에 파이썬보다 난이도가 엄청 어렵고 거지같음
C++
C를 기반으로 이것저것 하게 하는
컴퓨터의 많은 기능을 오롯이 사용할 수 있다면 포텐셜이 되게 높음
(흔히 고급개발자들)
훨씬 더 높은 퍼포먼스를 낼 수 있게 개발자가 직접 디자인할 수 있다
(Python은 이게 안됨)
Python
접근성을 높인것
C-python? C언어로 구성되어있음
나아아중에 가면 GIL에서 Python의 한계가 옴
GIL(Global Interpreter Lock)
모든 친구들이 순서를 지키면서 실행이 됨
= 병렬처리를 안되는 태생적 한계가 있음
그래서 multi 뭐시기 할꺼면 C++
Python에서 multi-processsing 은 가능하지만 multi-threading은 불가
그래서 tensorflow 등 라이브러리 불러오면 실제로는 C++의 코드를 실행하는 것이다.
어떤 일을 가느냐에 따라 c++을 공부해야하는지 시기가 다름
(현존하는 프로그래밍 중에 제일 어려움, 10년은 쳐야..)
Python이 노잼이다 = c++ 찍먹해주면 python의 소중함을 느낄 수 있다.
처음에는 심플하게는 컴퓨터의 성능 차이 >>> 코드의 문제까지 감
https://github.com/pybind/pybind11
Point. 딥러닝을 할 때 알아두면 좋다
Q. 언어의 레벨
사람에 가까울수록 high, 하드웨어에 가까우면 low
low - 어셈블리어
middle - C
high - 나머지 다
급을 나누는 것은 의미가 없음, 철학 차이.
어떻게 쓰느냐, 어디에 쓰느냐에 따라 전부 다 다르다
유사도 계산 관련
점 = 벡터
데이터 = 벡터 (나중에 설명해줄테니 외워라)
ex) 영화 추천
정보요소 - 장르, 분위기, 분류, 배우, 감독 ...
영화를 벡터로 만들고, 다른 영화도 벡터로 만들면 숫자화됨
벡터끼리의 계산해 가장비슷한 값 순서대로 추천하는것
contents-based filtering
이 영화들을 수치로 표현에서 수치상 거리가 가깝다.
내 생각) 요소별 차원을 구성해(행렬구성) euclidean distance로 거리를 계산하면 유사도를 추정할 수 있다
Euclidean_distance
https://en.wikipedia.org/wiki/Euclidean_distance
Euclidean distance - Wikipedia
From Wikipedia, the free encyclopedia Length of a line segment Using the Pythagorean theorem to compute two-dimensional Euclidean distance In mathematics, the Euclidean distance between two points in Euclidean space is the length of the line segment betwee
en.wikipedia.org
def euclidean_distance(x, y):
# x, y : np.array (n-dim vector) > 구현이 쉬워서 numpy가 좋음
return np.sqrt(np.sum(np.square(x - y)))
v1 = np.array([1,0])
v2 = np.array([0,1])
euclidean_distance(v1, v2)
# 1.4142135623730951cosine_distance
https://en.wikipedia.org/wiki/Cosine_similarity
n1 =np.linalg.norm(x)
- np.linalg.norm: NumPy 라이브러리의 선형 대수 모듈에 속한 함수로, 벡터의 크기를 계산
- x: 크기를 계산하려는 벡터
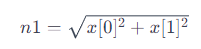
# 둘은 같다
n1 = np.linalg.norm(x)
n1 = np.sqrt(np.sum(np.square(x)))#cosine_distance
## TO-DO ##
# 주어진 x, y에 대해서 x,y 사이의 cosaine distance 를 계산
# 이론상 최솟값은 0, 최대값은 2
## cosaine distance는 1 - cosaine similarity 로 정의
def cosine_distance(x, y):
n1 =np.linalg.norm(x) # 벡터크기를 계산
n2 =np.linalg.norm(y)
cosine_sim = (x @ y) / (n1 * n2)
return 1 - cosine_sim
v1 = np.array([1,0])
v2 = np.array([0,1])
v3 = np.array([1, 2, 3, -4])
v4 = np.array([-1, 2, 5, 1])
print(cosine_distance(v1,v2))
print(cosine_distance(v3,v4))
# 1.0
# 0.5409219149512329
EDA 끝나고 데이터 분석을 위한 선형대수학 진행예정
numpy 복습하는 용도로 연습문제 풀고 질문주면 될 듯 함
Pandas
1.5.3 사용
파일경로
http://localhost:8888/notebooks/Desktop/AI_Lab/jupyter/Pandas/1.%20Pandas%20%EA%B8%B0%EC%B4%88(%EC%8B%A4%EC%8A%B5).ipynb#1.-Pandas-DataFrame-and-Operations
내년정도가 되면 2 점대로 이전할듯함
여담)
Pytorch 2.0으로 업데이트됨 / 1점 - 2점대 이동하며 100% 호환하게 바뀜
특정 column을 가져오기 > 무조건 columns 이름만 가능 = index 불가
df.info()
dataframe에 대한 기본적인 요약 정보를 볼 수 있다.
<class 'pandas.core.frame.DataFrame'>
DatetimeIndex: 10 entries, 2024-01-01 to 2024-01-10
Freq: D
Data columns (total 3 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 X1 10 non-null float64
1 X2 10 non-null float64
2 X3 10 non-null float64
dtypes: float64(3)
memory usage: 320.0 bytes
df.describe()
dataframe에 대한 전체적인 통계정보를 보여줌
cf. series
df.sort_values(by='X1')
X1 기준 오름차순 정렬 | 내림차순은 ascending=False 추가
Kaggle (해외)
AI를 잘한다는 것을 입증하기 어려움
프로젝트를 많이 하는 것도 어렵고, 내부 사정 알기 전엔 맞춰서 할 수 있는게 별로 없음
그래서 캐글을 많이함. 몇등으로.
Progression
Contributer
(열심히하면 됨)
Expert
4개 section에서 메달을 받으면
쉬운정도 Discussion > Datasets > notebook > competition)
Master
1개 골드
GrandMaster
솔로 1개 포함 총 5개 골드메달
점수를 저렇게 까지해서 점수를 얻는게 도움이 되는가?
코테 생각하면 비슷함. 캐글 잘하면 현업 잘함(토익 잘하면 영어를 못한다고는 하지 않음)
학생과 학부생은 프로젝트로는 도움이 안된다.
> 제대로 된 것을 할려면 실제 데이터를 가지고 해야될 것이 필요함 = 검증된 Kaggle 사용하는 이유
여담, NVIDIA 직원들이 계속 참여하고 있다.
혼자 1등, 2등했을 때 점수를 많이 줌
hoyso48 대한민국 캐글 1위
Limerobot 전체 랭킹 12위였었음. 역대 최장기간 Grandmaster > 현재 Upstage 재직중
Chris Deotte 올타임 레전드 Nvidia 직원 (정신적 지주, 코드공유)
DACON (한국)
우리가 일상적으로 사용하는 데이터가 많아서 좋음
cf. 아마 1월 2월 ML 프로젝트를 진행할 때 대회에 참여할 예정
풀강일때는 이러한 timeline으로 강의 진행된다고 보면됨
pd의 많은 read 함수를
# Q1. 생존자 비율
titanic.Survived.value_counts(normalize=True)
0 0.616162
1 0.383838
Name: Survived, dtype: float64
# Q2. 여성 승객
titanic.Sex.value_counts()
male 577
female 314
Name: Sex, dtype: int64
pandas에서 key : 위치를 추정할 수 있는 정보. column, index
Fancy Indexing
방법 1.
!! pandas는 numpy를 가져오기 때문에 broadcasting이 가능해서 boolean mask 적용가능
(대략적인 작동 구조 기억하기)
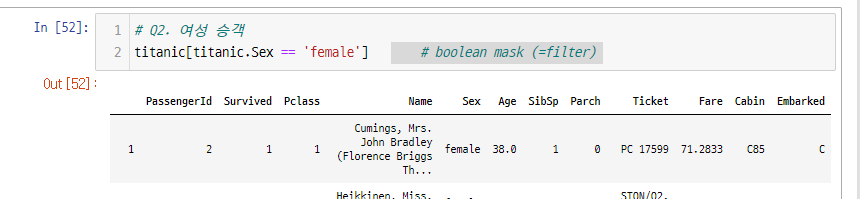
# Q2. 여성 승객
titanic.Sex == 'female' # boolean mask (=filter)
0 False
1 True
2 True
3 True
4 False
...
886 False
887 True
888 True
889 False
890 False
Name: Sex, Length: 891, dtype: bool
이것을 조건처럼 사용해서 데이터 필터링 가능

방법 2.
Q. 같은 데이터에 접근하는 방식(loc, fancy indexing 등)이 많은 것 같은데 보통 협업할 때 특정 방식을 정해놓고 사용하나요? (이대희 님)
A. 딱히 정해놓고 사용하지는 않음. 상황에 따라 다양한 곳에서 끌고오기 때문에 규칙을 정해놓지는 않음. 다만 loc를 쓸 수 있으면 모든 것을 구현할 수 있는 느낌이다.
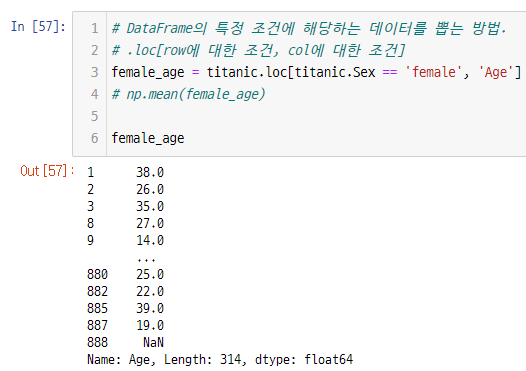
# Q3. 남성 승객들 중에서 가장 운임료(fare)
male_fare = titanic.loc[titanic.Sex == 'male', 'Fare']
np.max(male_fare)
512.3292
substring matching

regex : regular expression 정규 표현식
(gpt가 잘해주니까 외울필요는 없음)
# Q4. 이름에 Mrs. 가 포함된 사람 찾기 (=기혼 여성이 몇명인지 찾기)
#substring matching
titanic[titanic.Name.str.contains('Mrs')]
결측치 NaN
머신러닝 = 연산
연산을 통해 숫자를 찾아야하는데 결측값 있을 때는 채워줘야함
# 원하는 조건을 boolean mask로 만들고 뽑아내면 됨
# Q5. 결측치(NaN)가 포함된 모든 데이터 찾기
titanic[titanic.isnull().any(axis=1)]
708 rows × 12 columns
titanic.isnull().sum() # 각 column별 결측치 개수
. isnull() : true = 1, false = 0
.sum() : 합
titanic.isnull().mean () # 각 column별 결측치 비율
dataframe에서 boolean mask 이용 indexing은 말 그대로 index만 지원
= columns 은 안됨
= index가 같아야 데이터 뽑힘

여담)
다음주에 eda 프로젝트 부터는 강의장을 오픈하며 EDA는 팀플로 진행됨
오프라인으로 오면 커피 사드림. 1기도 볼 수 있음
Q. 여기 drop 메소드는 오브젝트를 직접 변경하지는 않잖아요. 그런데 메소드들 중에 오브젝트를 직접 변경하는 것들도 있는데 두가지를 구분하는 용어가 있나요? (윤상원 님)
A. 보통은 inplace라는 옵션을 씀. 근데 여러분은 쓰지마라. 오브젝트에 적용이 되버림.
결론 : inplace를 쓴다고 해서 메모리적 이득은 없음
결론2 : 덮어쓰는 방식이 젤 편함 (overwrite)
assignment operation을 통해서 value가 update가 될 수 있는지 여부
- mutable object : List, set, dict
- immutable object : int, float, str, tuple
numpy, panda object is mutable = 데이터 잘못 건들면 다시 불러와야함
call by object
call by object -> mutable object의 경우 call by reference로 작동
immutable object의 경우 call by value로 작동 (넘어간 parameter가 바뀌진 않음)
참고) C 언어계열 컴파일러 언어처럼 값을 담궈놓기 vs Python은 reference로 구현
= int, str이 immutable object인 이유
a= 10
print(id(a)) # 1번값
a= 5
print(id(a)) # 2번값
# 1번값 != 2번값 > reference 구조로 동작하는 Python 방식이번주 금요일 진행할 내용 소개
https://www.kaggle.com/c/instacart-market-basket-analysis/data
Instacart Market Basket Analysis | Kaggle
www.kaggle.com
캐글 가입 및 competition 참여 필요 > 개별로 다운 필요
시간나면 데이터 미리보고 오면 좋을듯함
2.5. Pivot Table을 이용하여 데이터 살펴보기
- pivot table이란 기존 테이블 구조를 특정 column을 기준으로 재구조화한 테이블을 말합니다.
- 특정 column을 기준으로 pivot하기 때문에, 어떤 column에 어떤 연산을 하느냐에 따라서 만들어지는 결과가 바뀝니다.
- 주로 어떤 column을 기준으로 데이터를 해석하고 싶을 때 사용합니다.
기본 틀 예시
# 성별을 기준으로 생존률 파악 --> Mean vs Sum
pd.pivot_table(data=, index=, columns=, values=, aggfunc=)
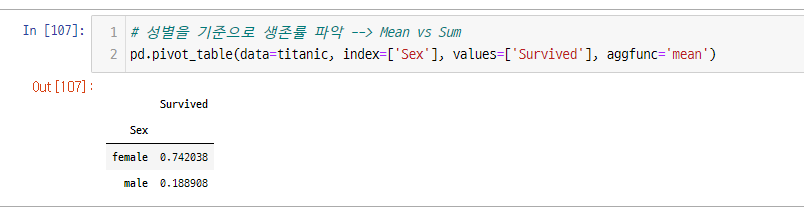
여기서 Survived는 각 성별에 따른 모수가 차이가 남
우리가 생각하는 것과 다름

데이터 분석은 수치 값을 가지고 논리과정을 펼치는것
EDA가 중요한 이유
ML, DL approach에
여러 수치 값을 뽑고 반영하는 과정으로 활용할 수 있음
EDA - Business 레벨 포커스
ML -
DA, DS 로서 일할꺼면 EDA 잘해야함 = Pandas 잘써야함
정답이 없는 문제임, EDA는 하다보면 상식선에서 인사이트가 나옴
데이터 보고 어떤 인사이틀 볼지 생각.
추천하는 것 : 되면 되는거.
주의해야할 점은 halucination 여부를 판단해야됨
실제로 생각한대로 구현이 되는건지 > 갖고와서 내가 원하는 기능으로 수정 & 판단 진행 필요
기능으로서 활용 (핵심 로직기술로서 활용 지양)
2.3. 여러 DataFrame 합치기
- SQL(Structure Query Language: 데이터베이스용 언어) Join(inner, left, outer)
- <=> merge
dictionary의 key값 = column
insta
금요일(23.12.29)
Seaborn 2시간, Instacart EDA
추후 주제 등등 간단하게 공유할 예정
'일별 학습일지' 카테고리의 다른 글
| 01/12 :: EDA 프로젝트 (0) | 2024.01.12 |
|---|---|
| 12/29 :: Instacart Market Data (0) | 2023.12.29 |
| 12/26 :: 개인 프로젝트 발표 (0) | 2023.12.26 |
| 12/26 :: 실강 (0) | 2023.12.26 |
| 12/21 :: 개발 1 (0) | 2023.12.22 |


