https://visioneer.notion.site/visioneer/AI-7e3930898a3b43deb206adf821f6055c
코랩 학습일지
Data Analysis
통계지식 필요 + 도메인(메인) + 데이터 + 분석스킬
PM으로서의 DS, DA
우리의 영역이 아니긴하다.
DS DA를 디테일하게 구분하는 회사는 data를 다루는 회사임
AI 엔지니어중 벡엔드 = 고연봉자 많음
카카오화재
데이터를 분산해두지 않아서 피해가 컸음
> 분산해두는 기술 hadoop
Data Visualizaiton 시각화
사용 패키지
- 대화형 파이썬 툴
- 통계 및 수학 계산용 라이브러리 Numpy
- 데이터 핸들링 = 데이터 정제(전처러) : Pandas / SQL / 태블로
시각화 > 설득 / 히든패턴 발견
Matplotlib > seaborn > plotly
어떤걸 많이 쓰는지는 kaggle을 가서 사람들이 많이 작성하는 코드를 본다.
머신러닝 / 딥러닝 > 미래 예측
데이터 분석을 배우는 이유. 본질을 찾는 것
https://colab.research.google.com/drive/1M5MgWim-lXFTxSYi5simk9tiJa_Uo5hH?usp=sharing
보통 큰 라이브러리는 공식페이지 데이터가 되게 잘 되어있음

Data Selection 이 중요하다
컬럼명에 따라 원하는대로 데이터를 가져와 처리하는 기술
glassdoor
와인데이터
데이터를 어떻게 녹여낼 수 있을까
책 추천 : Yes 24. 데이터는 어떻게 인생의 무기가 되는가
https://www.sedaily.com/NewsView/1Z2YA6MNWR
그거, 저거 > 좀더 명시적인 단어 사용하면 좋을듯함
NaN 결측 데이터는 split 못함 = 결측제거 후 진행필요
dropna.
서울시 상관분석 데이터 sheet, api로 다 나와있음
오픈업 : 상권정보 사이트
데이터 들여다보고
심리학 공부를 많이 했던 것 같다.
KDI 한국개발연구원(통계청 데이터를 열심히 시각화 해주는중
dpi 옵션이 있으면 고해상도로 나옴(좋은 Tip인듯)
Scatter plot
활용예시 : 카카오 얼굴인식 >
데이터를 조작한게 아니라, 관점을 뒤집어서 보여주는 것일 뿐
유리하게 수정을 해서 발표를 하곤 함.
* 리눅스 기반 코랩에서 나눔 한글폰트 설치하는 방법
!sudo apt-get install -y fonts-nanum
!sudo fc-cache -fv
!rm ~/.cache/matplotlib -rf
일반 블로그에 있는 내용은 이해를 하기 쉬우나,
현업에 적용하기 위해선 공식문서에 적응하는 연습을 해야된다.
dataframe을 다루는 방법에 익숙해져야할듯
matplotlib은 발표보다는 빠르게 시각화해서 간단하게 보고,
공유하거나 share 할 떄는 seaborn 등 다른 라이브러리로 활용을 한다.
IT 섹터 > 인생에서의 되게 중요한 변곡점.
나는 4시간만 일한다. > 되겠네? 하면서 많이 바뀜 // 공간적 자유를 가지고 얻는게 되게 중요하다.
공간적 자유 = 재택근무
한달정도 재택도 많이하고 디지털 노마드도 많이 해봤음.
장소만 바뀔뿐이지 일은 열심히 해야한다.
개발자는 이런 것들이 가능하다.
패시브 인컴 확보하기 좋다 (5개 정도 된다) > 급여정도는 벌 수 있다.
구글 ad센스 광고비(트랙픽 만드는 용도)
자본주의에서 여러부늘 부자로 만들어 주는 것. 경험 + 쌓이면 플러스가 됨
데이터 컨설팅
이런게 커지면 컨설팅, 광고 대행사가 되는 것
Seaborn
seaborn: statistical data visualization — seaborn 0.13.0 documentation
seaborn: statistical data visualization
seaborn.pydata.org
시간이 오래걸리지만 데이터를 보여주기엔 도움이 된다.
df = sns.load_dataset?
도움말에서 링크 들어가면 sample data.csv들이 많음 > 연습하기 좋겠다
데이터를 볼 때 EDA 부터 천천히
df.info(), df.describe() 로 데이터 특성 파악
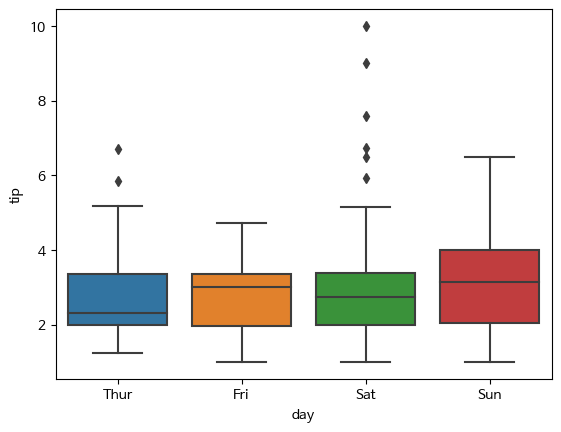
박스 최하단 line = min value / 최상단 line = max value
점 = 예외값 / 아래부터 4분위
간단하게 반복문 써서 많이 그려도됨

heatmap이 단순히 상관관계를 표시하는 방법은 아님
시계열 데이터 시각화에 유용함
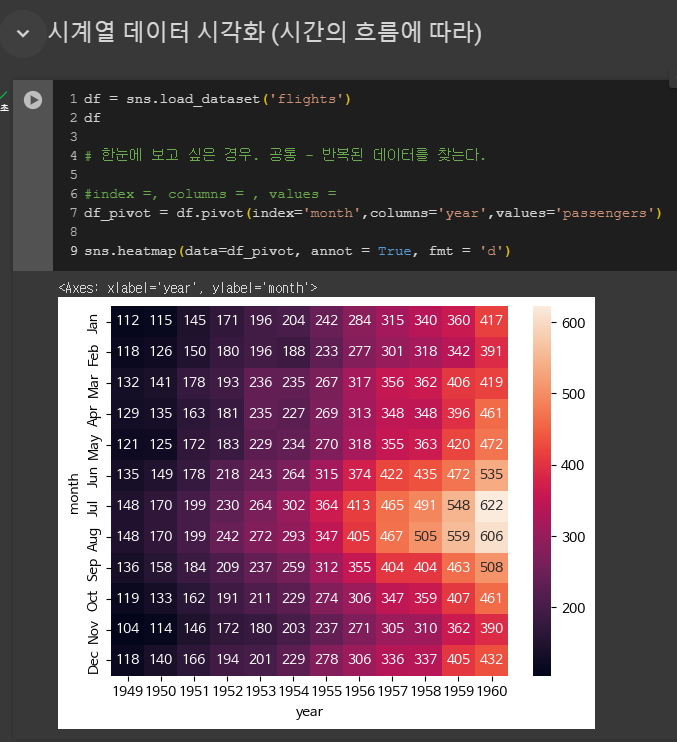
annot?

시각화는 다음 모듈에서도 계속 하게될 거임
Q. 보통 선형관계가 얼마나 되야 높다가 할 수 있나요?
A.
0.5정도이상이면 높다고 하는데, 사람마다 다르고 경험상 0.5가 넘어가면 관계가 있다고 보인다.
0.7이면 같이 움직이는 모습을 볼 수 있다.
감을 찾는 것이 필요함
캐글 금메달 따면 카카오브레인에서 연락 바로옴
test, train으로 나뉜 이유는 모델링을 하기 위해서임
여담. 본인은 이제 대회를 나가는 것보다는 프젝에 집중하는 편임
의견 : tabular dataset 모델링하는 것 재밌다.
정규표현식 작성하는 연습 필요
처음에 공부할 때 주의할 점..
탐구하는 것은 좋으나, 올바른 파트를 파는 것이 맞나 생각해야됨
내일부터 Python 프로젝트는 오전에 잠깐 Flask에 대한 강의를 진행하고 하려함
백엔드에 대한 이해도가 높으면 좋음
내 트랙에서 어떤 길을 가야할까
AI holic 인공지능 트랙으로 가게 만들어준분 : 송호연 NFT bank
https://www.youtube.com/@ChrissSong
네이버 - 카카오 리드 - NFT AI 부사장(2021년 기사)
NFT 뱅크 투자
시리즈 A투자유치 작은 회사 쉽지 않음
쿠팡도 사람을 짜르고 토스도 짜름 = 안전한 곳은 없다
토스는 1조밸류일 때 1억 스톡옵션을 줌
df.
백엔드에서 머신러닝 엔지니어 커리어 전환 > 꼭 보기
코딩으로 건든건 터미널 상에서만 적용됨
cf. inplace=True 넣어줘야 원본에 적용됨
눈으로 모델링 한 코드들 찍어보면 좋다.
https://visioneer.notion.site/7ba41b266d1a4949b278333eb4b80851
파이썬 프로젝트 | Built with Notion
1. stt, tts 라이브러리를 활용한 음성인식 비서 개발
visioneer.notion.site
파이썬 프로젝트 관련 노션
기획을 하는 것
금융쪽에 관심이 있으면 퀀트 쪽 만들어보는 것도 좋음
콴텍 알고리즘
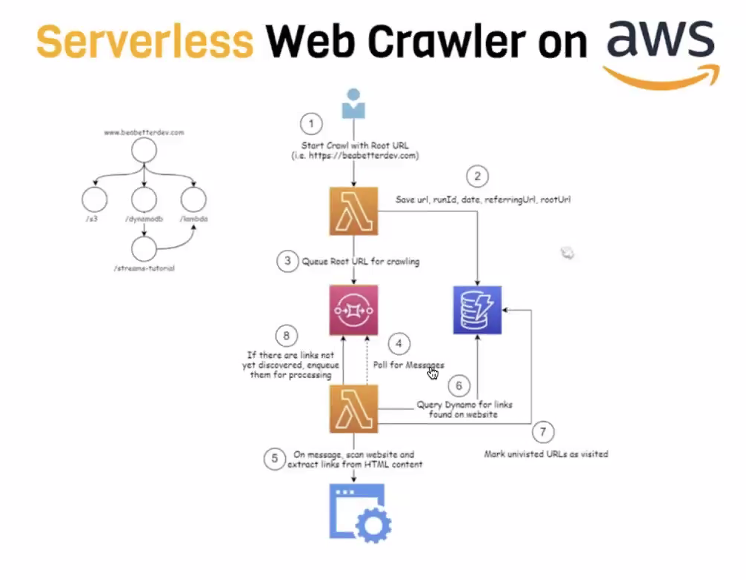
open ai 요청 같은 케이스도 있음
1. Python을 가지고 프로그램을 만들어 보는 것
2. 회사에 어필할 수 있을만한 프로젝트 수준
'일별 학습일지' 카테고리의 다른 글
| 12/21 :: Ideation 2 (0) | 2023.12.21 |
|---|---|
| 12/20 :: Ideation (0) | 2023.12.20 |
| 12/13 :: 실시간 (0) | 2023.12.13 |
| 12/12 :: IF, for, while (0) | 2023.12.12 |
| 12/11 :: Data type (0) | 2023.12.12 |


